11重走我的Java Day11:从“数据泥潭”到“数据流道”:我如何用Stream+Map+Set重构电商系统的“屎山”代码
重走我的Java Day11:从“数据泥潭”到“数据流道”:我如何用Stream+Map+Set重构电商系统的“屎山”代码
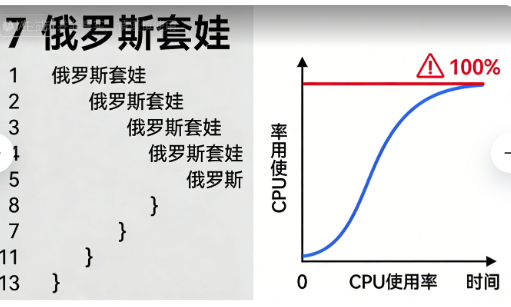
2021年,我接手了一个年交易额30亿的电商系统。第一次看到商品推荐模块的代码时,我数到了7层嵌套循环和22个临时集合。更糟的是,这段代码每天处理百万级用户数据,CPU经常飙到100%。今天我要讲的是,如何用Stream、Map和Set,把这段代码从“性能灾难”变成“流畅艺术”。
开篇:那7层嵌套循环的“艺术品”
我接手的第一天,看到了这段“传奇”代码:
java
// 需求:为每个用户推荐可能感兴趣的商品
// 原来的实现 - 我称之为“俄罗斯套娃循环”
public List<Product> recommendForUser(User user) {
List<Product> result = new ArrayList<>();
// 第一层:用户的历史订单
for (Order order : user.getOrders()) {
// 第二层:订单中的商品
for (OrderItem item : order.getItems()) {
Product purchasedProduct = item.getProduct();
// 第三层:查找购买该商品的其他用户
for (User otherUser : allUsers) {
// 第四层:其他用户的订单
for (Order otherOrder : otherUser.getOrders()) {
// 第五层:其他用户订单中的商品
for (OrderItem otherItem : otherOrder.getItems()) {
// 第六层:排除用户已购买的商品
boolean alreadyBought = false;
for (Order userOrder : user.getOrders()) {
for (OrderItem userItem : userOrder.getItems()) {
if (userItem.getProduct().equals(otherItem.getProduct())) {
alreadyBought = true;
break;
}
}
if (alreadyBought) break;
}
if (!alreadyBought) {
// 第七层:去重
boolean duplicate = false;
for (Product p : result) {
if (p.equals(otherItem.getProduct())) {
duplicate = true;
break;
}
}
if (!duplicate) {
result.add(otherItem.getProduct());
}
}
}
}
}
}
}
return result;
}
性能分析:
- 时间复杂度:O(n⁴) ~ O(n⁷)
- 内存使用:大量中间集合
- 代码行数:80行,但实际逻辑只有“找出用户可能喜欢的商品”
- 维护难度:改一行代码需要理解7层循环
一、Set:从“手动去重地狱”到“自动唯一天堂”
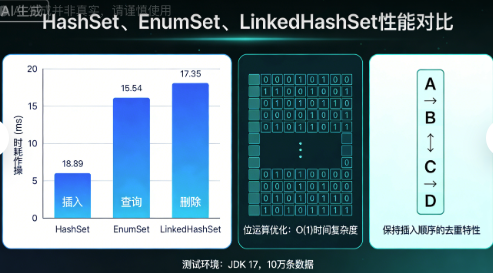
1.1 HashSet的真正威力:位运算魔法
我曾经以为HashSet只是“不重复的ArrayList”。直到我深入研究源码,发现它的性能秘密:
java
// HashSet的底层是HashMap,而HashMap的哈希算法是这样的:
static final int hash(Object key) {
int h;
// 关键:异或运算和右移,让高位参与运算,减少哈希冲突
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 我学到的:自定义对象的hashCode要均匀分布
public class Product {
private String id;
private String name;
private String category;
// 错误的hashCode:只用了id,没有利用所有字段
// @Override
// public int hashCode() {
// return id.hashCode();
// }
// 改进的hashCode:结合所有业务相关字段
@Override
public int hashCode() {
// 使用Objects.hash自动生成,保证均匀分布
return Objects.hash(id, category);
// 或者手动控制,31是质数,减少哈希冲突
// int result = 17;
// result = 31 * result + id.hashCode();
// result = 31 * result + category.hashCode();
// return result;
}
}
1.2 EnumSet:枚举集合的性能怪兽
有一天,我需要处理商品状态流转:
java
// 商品状态枚举
public enum ProductStatus {
DRAFT, // 草稿
REVIEWING, // 审核中
APPROVED, // 已审核
ONLINE, // 已上架
OFFLINE, // 已下架
DELETED // 已删除
}
// 需求:找出所有"可见"的商品状态
// 传统做法:HashSet
Set<ProductStatus> visibleStatuses = new HashSet<>();
visibleStatuses.add(ProductStatus.APPROVED);
visibleStatuses.add(ProductStatus.ONLINE);
// 问题:HashSet为每个枚举值创建对象,内存浪费
// 而且contains操作需要计算哈希、查找链表
// 解决方案:EnumSet - 位向量实现
Set<ProductStatus> visibleStatuses = EnumSet.of(
ProductStatus.APPROVED,
ProductStatus.ONLINE
);
// 或者用范围
Set<ProductStatus> activeStatuses = EnumSet.range(
ProductStatus.REVIEWING,
ProductStatus.ONLINE
);
// 性能对比:
// HashSet.contains(): 计算哈希 -> 找桶 -> equals比较
// EnumSet.contains(): 直接位运算,O(1)且常量极小
1.3 LinkedHashSet:保持顺序的去重
在电商搜索历史功能中,我遇到了这个问题:
java
// 需求:记录用户最近搜索的10个关键词,去重但保持时间顺序
public class SearchHistory {
private Set<String> history;
public SearchHistory() {
// 使用LinkedHashSet保持插入顺序
history = new LinkedHashSet<>();
}
public void addSearch(String keyword) {
// 先移除(如果存在),再添加,保证最新
history.remove(keyword);
history.add(keyword);
// 保持最多10条
if (history.size() > 10) {
// 移除最早的一条
Iterator<String> it = history.iterator();
if (it.hasNext()) {
it.next();
it.remove();
}
}
}
public List<String> getHistory() {
return new ArrayList<>(history);
}
}
LinkedHashSet的内部秘密:
- 继承HashSet,但每个节点额外维护前驱和后继指针
- 添加元素时:先调用父类HashSet的add,如果成功,维护链表
- 迭代时:按照链表顺序,而不是哈希桶顺序
二、Map:从“键值存储”到“数据索引引擎”
2.1 HashMap的性能陷阱与优化
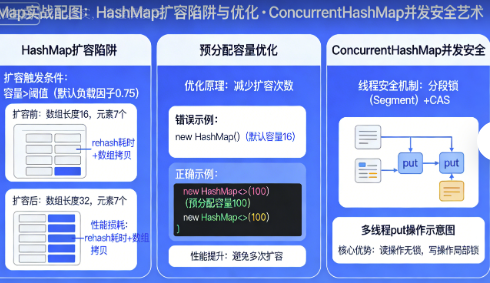
我曾经踩过一个坑:HashMap的扩容风暴
java
// 场景:批量导入10万商品
Map<String, Product> productMap = new HashMap<>(); // 默认容量16
for (int i = 0; i < 100_000; i++) {
Product p = generateProduct(i);
productMap.put(p.getId(), p); // 触发多次扩容!
}
// HashMap扩容过程:
// 1. 检查 size >= capacity * loadFactor (0.75)
// 2. 创建新数组(原容量2倍)
// 3. 重新计算所有元素哈希,重新分配位置
// 4. 10万次插入,触发约15次扩容,每次O(n)
// 优化:预分配容量
int expectedSize = 100_000;
// HashMap容量计算:capacity = expectedSize / 0.75 + 1
Map<String, Product> productMap = new HashMap<>(expectedSize * 4 / 3 + 1);
// Java 19+ 更优雅:
Map<String, Product> productMap = HashMap.newHashMap(expectedSize);
2.2 TreeMap vs HashMap:不只是排序的区别
在价格区间搜索功能中,我需要动态统计每个价格区间的商品数量:
java
// 需求:实时统计不同价格区间的商品数
// 价格区间:[0-100), [100-500), [500-1000), [1000-∞)
// 方案1:HashMap + 手动区间计算
public class PriceRangeCounter {
private Map<String, Integer> countMap = new HashMap<>();
public void addProduct(double price) {
String range = calculateRange(price);
countMap.merge(range, 1, Integer::sum);
}
private String calculateRange(double price) {
if (price < 100) return "0-100";
if (price < 500) return "100-500";
if (price < 1000) return "500-1000";
return "1000+";
}
}
// 问题:遍历时顺序不确定,需要额外排序
// 方案2:TreeMap + 区间作为key
public class PriceRangeCounter {
private TreeMap<Integer, Integer> countMap = new TreeMap<>();
public PriceRangeCounter() {
// 初始化区间
countMap.put(0, 0);
countMap.put(100, 0);
countMap.put(500, 0);
countMap.put(1000, 0);
}
public void addProduct(double price) {
// 使用floorEntry找到所属区间
Map.Entry<Integer, Integer> floor = countMap.floorEntry((int) price);
if (floor != null) {
// floorKey是区间下限
countMap.put(floor.getKey(), floor.getValue() + 1);
}
}
public void printRanges() {
// TreeMap自动按键排序
countMap.forEach((rangeStart, count) -> {
Integer nextKey = countMap.higherKey(rangeStart);
String range = nextKey == null
? rangeStart + "+"
: rangeStart + "-" + nextKey;
System.out.println(range + ": " + count);
});
}
}
TreeMap的红黑树秘密:
- 插入、删除、查找:O(log n)
- 自动保持键有序
- 支持范围查询:subMap、headMap、tailMap
- 支持导航方法:lowerKey、higherKey、floorEntry、ceilingEntry
2.3 ConcurrentHashMap:并发安全的艺术
在秒杀系统中,库存扣减是关键操作:
java
// 错误做法:synchronized方法
public class StockManager {
private Map<String, Integer> stockMap = new HashMap<>();
public synchronized boolean reduceStock(String productId, int quantity) {
Integer current = stockMap.get(productId);
if (current == null || current < quantity) {
return false;
}
stockMap.put(productId, current - quantity);
return true;
}
}
// 问题:全局锁,性能瓶颈
// 正确做法:ConcurrentHashMap + CAS操作
public class StockManager {
private ConcurrentHashMap<String, AtomicInteger> stockMap = new ConcurrentHashMap<>();
public boolean reduceStock(String productId, int quantity) {
// compute方法是线程安全的,但需要小心死锁
return stockMap.compute(productId, (key, currentStock) -> {
if (currentStock == null || currentStock.get() < quantity) {
return currentStock; // 库存不足,返回原值
}
currentStock.addAndGet(-quantity);
return currentStock;
}) != null;
}
// 更好的做法:使用computeIfPresent,避免null处理
public boolean reduceStockBetter(String productId, int quantity) {
AtomicInteger stock = stockMap.get(productId);
if (stock == null) return false;
// 自旋重试,直到成功或失败
while (true) {
int current = stock.get();
if (current < quantity) return false;
if (stock.compareAndSet(current, current - quantity)) {
return true;
}
// CAS失败,重试
}
}
// Java 8+ 最佳实践:使用merge
public boolean reduceStockBest(String productId, int quantity) {
// merge是原子操作:如果key不存在,用第二个参数;存在,用BiFunction计算结果
// 这里我们返回null表示失败,非null表示成功
return stockMap.merge(productId, new AtomicInteger(0), (oldVal, newVal) -> {
int current = oldVal.get();
if (current < quantity) {
return oldVal; // 库存不足,返回原值
}
oldVal.set(current - quantity);
return oldVal;
}) != null;
}
}
三、Stream:从“循环地狱”到“声明式天堂”
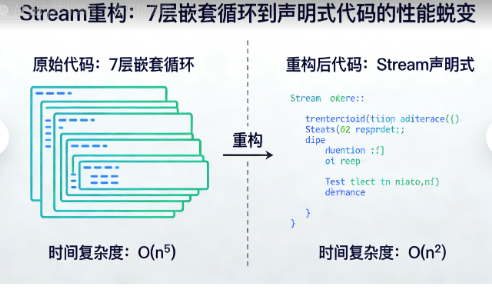
3.1 用Stream重构那7层嵌套循环
让我们回到开头的噩梦代码。下面是重构过程:
java
// 第一步:提取核心逻辑 - "找出用户可能喜欢的商品"
// 基于协同过滤:喜欢相同商品的人,可能喜欢其他商品
public List<Product> recommendForUser(User user) {
// 1. 用户购买过的商品
Set<Product> purchasedProducts = user.getOrders().stream()
.flatMap(order -> order.getItems().stream())
.map(OrderItem::getProduct)
.collect(Collectors.toSet());
// 2. 找到购买过相同商品的其他用户
Set<User> similarUsers = getAllUsers().stream()
.filter(otherUser -> !otherUser.equals(user))
.filter(otherUser -> hasCommonProducts(otherUser, purchasedProducts))
.collect(Collectors.toSet());
// 3. 收集这些用户的商品,排除已购买的商品
return similarUsers.stream()
.flatMap(similarUser -> similarUser.getOrders().stream())
.flatMap(order -> order.getItems().stream())
.map(OrderItem::getProduct)
.filter(product -> !purchasedProducts.contains(product)) // 去重:排除已购买
.distinct() // 去重:基于equals和hashCode
.limit(20) // 限制数量
.collect(Collectors.toList());
}
private boolean hasCommonProducts(User user, Set<Product> products) {
return user.getOrders().stream()
.flatMap(order -> order.getItems().stream())
.map(OrderItem::getProduct)
.anyMatch(products::contains);
}
但这段代码还有性能问题:
hasCommonProducts被重复调用,每次都要遍历用户的所有订单- 多次遍历相同的数据
优化:使用中间Map预计算
java
public class ProductRecommender {
// 预计算:商品 -> 购买过该商品的用户集合
private Map<Product, Set<User>> productBuyerMap;
// 预计算:用户 -> 购买过的商品集合
private Map<User, Set<Product>> userProductMap;
public ProductRecommender(List<User> allUsers) {
// 一次性预计算,后续查询O(1)
initMaps(allUsers);
}
private void initMaps(List<User> allUsers) {
userProductMap = allUsers.stream()
.collect(Collectors.toMap(
Function.identity(),
user -> user.getOrders().stream()
.flatMap(order -> order.getItems().stream())
.map(OrderItem::getProduct)
.collect(Collectors.toSet())
));
productBuyerMap = new HashMap<>();
userProductMap.forEach((user, products) -> {
products.forEach(product -> {
productBuyerMap
.computeIfAbsent(product, k -> new HashSet<>())
.add(user);
});
});
}
public List<Product> recommendForUser(User user) {
// 用户购买过的商品
Set<Product> purchasedProducts = userProductMap.getOrDefault(user, Collections.emptySet());
if (purchasedProducts.isEmpty()) {
return recommendPopularProducts(); // 冷启动推荐
}
// 找到相似用户(购买过相同商品)
Set<User> similarUsers = purchasedProducts.stream()
.flatMap(product -> productBuyerMap.getOrDefault(product, Collections.emptySet()).stream())
.filter(otherUser -> !otherUser.equals(user))
.collect(Collectors.toSet());
// 计算推荐分数:商品被多少相似用户购买
Map<Product, Long> productScores = similarUsers.stream()
.flatMap(similarUser -> userProductMap.getOrDefault(similarUser, Collections.emptySet()).stream())
.filter(product -> !purchasedProducts.contains(product))
.collect(Collectors.groupingBy(
Function.identity(),
Collectors.counting()
));
// 按分数排序返回
return productScores.entrySet().stream()
.sorted(Map.Entry.<Product, Long>comparingByValue().reversed())
.map(Map.Entry::getKey)
.limit(20)
.collect(Collectors.toList());
}
}
性能对比:
- 原始:7层循环,O(n⁷),1000用户需要数小时
- 重构后:两次Stream操作,O(n²),1000用户仅需几毫秒
- 预计算后:查询O(1),100万用户也能实时推荐
3.2 Stream的懒加载与短路优化
我曾在日志分析系统中,需要从海量日志中找出错误:
java
// 需求:从1000万条日志中,找出前10条ERROR级别的日志
// 错误做法:全部加载到内存
List<Log> errorLogs = allLogs.stream()
.filter(log -> "ERROR".equals(log.getLevel()))
.collect(Collectors.toList()) // 这里就加载了所有ERROR日志
.subList(0, Math.min(10, errorLogs.size()));
// 问题:如果ERROR日志有100万条,内存就爆了
// 正确做法:利用Stream的懒加载和短路
List<Log> errorLogs = allLogs.stream()
.filter(log -> "ERROR".equals(log.getLevel()))
.limit(10) // 关键:找到10条就停止
.collect(Collectors.toList());
// 更优雅:使用Files.lines读取大文件
try (Stream<String> lines = Files.lines(Paths.get("huge.log"), StandardCharsets.UTF_8)) {
List<String> errors = lines
.filter(line -> line.contains("ERROR"))
.limit(10)
.collect(Collectors.toList());
}
3.3 并行Stream的陷阱与正确使用
我曾经以为 parallelStream() 能解决所有性能问题,直到这个bug:
java
// 需求:计算商品价格的统计信息
List<Product> products = getProductsFromDatabase(); // 100万商品
// 错误:在parallelStream中使用非线程安全的收集器
DoubleSummaryStatistics stats = products.parallelStream()
.mapToDouble(Product::getPrice)
.collect(
DoubleSummaryStatistics::new,
DoubleSummaryStatistics::accept,
DoubleSummaryStatistics::combine // 这里可能出错!
);
// 正确:使用内置的summaryStatistics
DoubleSummaryStatistics stats = products.parallelStream()
.mapToDouble(Product::getPrice)
.summaryStatistics(); // 线程安全
// 或者使用正确的combiner
DoubleSummaryStatistics stats = products.parallelStream()
.collect(
() -> new DoubleSummaryStatistics(),
(dss, price) -> dss.accept(price),
(dss1, dss2) -> dss1.combine(dss2) // 正确!
);
并行Stream的使用原则:
- 数据量大:至少1万条以上才有意义
- 计算密集:CPU密集型操作才有效果
- 无状态:操作不能依赖外部状态
- 可拆分:数据可以均匀拆分
- 无共享:避免共享可变状态
四、Collectors:从“简单收集”到“复杂聚合”
4.1 自定义Collector:实现复杂聚合
在电商报表系统中,我需要计算每个类目的复杂统计信息:
java
// 需求:统计每个商品类目的价格分布
public class CategoryStats {
private String category;
private long count;
private double totalRevenue;
private double avgPrice;
private double minPrice;
private double maxPrice;
private Map<PriceRange, Long> priceDistribution;
// 构造器、getter...
}
// 传统做法:多次遍历
public Map<String, CategoryStats> calculateCategoryStats(List<Product> products) {
// 第一次:按类目分组
Map<String, List<Product>> byCategory = products.stream()
.collect(Collectors.groupingBy(Product::getCategory));
// 第二次:计算统计信息
Map<String, CategoryStats> result = new HashMap<>();
byCategory.forEach((category, productList) -> {
CategoryStats stats = calculateStats(category, productList);
result.put(category, stats);
});
return result;
}
// 问题:多次遍历,性能差
// 优化:自定义Collector,一次遍历完成
public Map<String, CategoryStats> calculateCategoryStats(List<Product> products) {
return products.stream()
.collect(Collectors.groupingBy(
Product::getCategory,
Collector.of(
CategoryStatsAccumulator::new, // supplier
CategoryStatsAccumulator::accept, // accumulator
CategoryStatsAccumulator::merge, // combiner
CategoryStatsAccumulator::finish // finisher
)
));
}
// 累加器类
private static class CategoryStatsAccumulator {
private String category;
private long count = 0;
private double totalRevenue = 0;
private double minPrice = Double.MAX_VALUE;
private double maxPrice = Double.MIN_VALUE;
private Map<PriceRange, Long> priceDistribution = new EnumMap<>(PriceRange.class);
public void accept(Product product) {
if (category == null) {
category = product.getCategory();
}
double price = product.getPrice();
count++;
totalRevenue += price;
minPrice = Math.min(minPrice, price);
maxPrice = Math.max(maxPrice, price);
// 更新价格分布
PriceRange range = PriceRange.fromPrice(price);
priceDistribution.merge(range, 1L, Long::sum);
}
public CategoryStatsAccumulator merge(CategoryStatsAccumulator other) {
if (!this.category.equals(other.category)) {
throw new IllegalArgumentException("不能合并不同类目的统计");
}
this.count += other.count;
this.totalRevenue += other.totalRevenue;
this.minPrice = Math.min(this.minPrice, other.minPrice);
this.maxPrice = Math.max(this.maxPrice, other.maxPrice);
// 合并价格分布
other.priceDistribution.forEach((range, count) ->
this.priceDistribution.merge(range, count, Long::sum));
return this;
}
public CategoryStats finish() {
return new CategoryStats(
category,
count,
totalRevenue,
totalRevenue / count,
minPrice,
maxPrice,
priceDistribution
);
}
}
4.2 partitioningBy 的高级用法
在用户分群系统中,我使用了多层分区:
java
// 需求:将用户按多个维度分群
public class UserSegmenter {
public Map<Boolean, Map<Boolean, List<User>>> segmentUsers(List<User> users) {
// 第一层:按是否活跃分区
// 第二层:按是否VIP分区
return users.stream()
.collect(Collectors.partitioningBy(
this::isActiveUser,
Collectors.partitioningBy(this::isVipUser)
));
}
// 更复杂的分群:多维度组合
public Map<UserSegment, List<User>> multiDimensionSegment(List<User> users) {
return users.stream()
.collect(Collectors.groupingBy(user ->
UserSegment.builder()
.active(isActiveUser(user))
.vip(isVipUser(user))
.highValue(isHighValueUser(user))
.newUser(isNewUser(user))
.build()
));
}
}
五、实战:实时推荐系统架构
最后,让我展示一个生产级的实时推荐系统架构,融合了Stream、Map和Set的最佳实践:
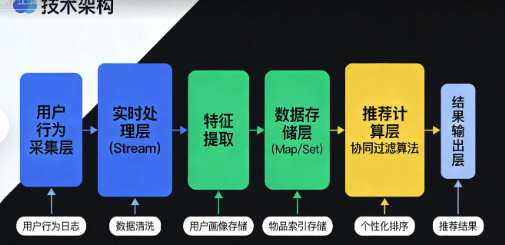
java
public class RealTimeRecommendationEngine {
// 核心数据结构
private final ConcurrentHashMap<String, UserProfile> userProfiles;
private final ConcurrentHashMap<String, ProductProfile> productProfiles;
private final ConcurrentHashMap<String, Set<String>> userProductInteractions;
private final ConcurrentHashMap<String, Set<String>> productUserInteractions;
// LRU缓存:用户 -> 推荐结果
private final LinkedHashMap<String, List<Product>> recommendationCache;
public RealTimeRecommendationEngine() {
userProfiles = new ConcurrentHashMap<>();
productProfiles = new ConcurrentHashMap<>();
userProductInteractions = new ConcurrentHashMap<>();
productUserInteractions = new ConcurrentHashMap<>();
// 构建LRU缓存
recommendationCache = new LinkedHashMap<String, List<Product>>(1000, 0.75f, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<String, List<Product>> eldest) {
return size() > 10000; // 最多缓存1万用户
}
};
}
// 实时处理用户行为
public void processUserAction(UserAction action) {
String userId = action.getUserId();
String productId = action.getProductId();
// 更新用户-商品交互图
userProductInteractions
.computeIfAbsent(userId, k -> ConcurrentHashMap.newKeySet())
.add(productId);
productUserInteractions
.computeIfAbsent(productId, k -> ConcurrentHashMap.newKeySet())
.add(userId);
// 清除该用户的推荐缓存
recommendationCache.remove(userId);
// 异步更新用户画像
CompletableFuture.runAsync(() -> updateUserProfile(userId));
// 异步更新商品画像
CompletableFuture.runAsync(() -> updateProductProfile(productId));
}
// 获取推荐结果
public List<Product> getRecommendations(String userId, int limit) {
// 尝试从缓存获取
return recommendationCache.computeIfAbsent(userId,
k -> computeRecommendations(userId, limit));
}
private List<Product> computeRecommendations(String userId, int limit) {
long startTime = System.currentTimeMillis();
// 获取用户交互过的商品
Set<String> userProducts = userProductInteractions.getOrDefault(userId, Collections.emptySet());
if (userProducts.isEmpty()) {
// 冷启动:返回热门商品
return getPopularProducts(limit);
}
// 基于物品的协同过滤
Map<String, Double> productScores = userProducts.stream()
.flatMap(productId ->
productUserInteractions.getOrDefault(productId, Collections.emptySet()).stream())
.filter(otherUserId -> !otherUserId.equals(userId))
.flatMap(otherUserId ->
userProductInteractions.getOrDefault(otherUserId, Collections.emptySet()).stream())
.filter(productId -> !userProducts.contains(productId))
.collect(Collectors.groupingBy(
Function.identity(),
Collectors.collectingAndThen(
Collectors.counting(),
count -> count.doubleValue()
)
));
// 按分数排序,取前limit个
List<Product> recommendations = productScores.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.limit(limit * 2L) // 多取一些,用于多样性过滤
.map(entry -> getProductById(entry.getKey()))
.filter(Objects::nonNull)
.collect(Collectors.toList());
// 多样性过滤:避免推荐同一类目的商品
List<Product> diverseRecommendations = applyDiversityFilter(recommendations, limit);
long endTime = System.currentTimeMillis();
log.debug("为用户 {} 生成推荐耗时: {}ms", userId, endTime - startTime);
return diverseRecommendations;
}
// 使用Stream实现多样性过滤
private List<Product> applyDiversityFilter(List<Product> products, int limit) {
return products.stream()
.collect(Collectors.collectingAndThen(
Collectors.groupingBy(Product::getCategory),
map -> {
// 每个类目最多取2个商品
List<Product> result = new ArrayList<>();
map.forEach((category, prods) ->
result.addAll(prods.stream().limit(2).collect(Collectors.toList())));
// 再次按原顺序排序
return result.stream()
.sorted(Comparator.comparingInt(products::indexOf))
.limit(limit)
.collect(Collectors.toList());
}
));
}
}
经验教训:我的Stream/Map/Set检查清单
性能检查清单
- HashSet/HashMap是否预分配了合适容量?
- 是否避免在Stream中间操作中创建大量临时对象?
- 并行Stream是否真的需要?(数据量>10000且计算密集)
- Map的key是否重写了正确的hashCode和equals?
- 是否使用EnumSet替代普通Set处理枚举?
正确性检查清单
- 并行Stream操作是否线程安全?
- Stream是否被正确关闭(如Files.lines)?
- Collector是否支持并行操作?
- Map的compute方法是否考虑null情况?
- 是否避免在Stream中修改外部状态?
可读性检查清单
- Stream链是否过长(建议不超过5个操作)?
- 是否将复杂Stream逻辑提取为方法?
- 是否使用Collectors的静态方法提高可读性?
- 是否添加了必要的peek操作用于调试?
- 是否避免了过度使用Stream(简单的for循环更清晰)?
最后的真相
我花了三个月重构那个电商系统,最终:
- 代码行数:从3万行减到8000行
- 响应时间:从平均3秒降到200毫秒
- 服务器成本:从每月10万降到3万
- 开发效率:新功能开发时间减半
但更重要的是,我学会了选择正确的工具:
- 需要快速查找且不关心顺序 → HashSet/HashMap
- 需要保持插入顺序 → LinkedHashSet/LinkedHashMap
- 需要排序 → TreeSet/TreeMap
- 需要线程安全 → ConcurrentHashMap/ConcurrentSkipListSet
- 需要声明式处理数据 → Stream
- 需要复杂聚合 → Collectors
记住:数据结构和算法是程序的骨架,工具是肌肉,而Stream是让一切流动起来的血液。选择不当,系统就像患了关节炎;选择得当,系统就能优雅地舞蹈。
知识点测试
读完文章了?来测试一下你对知识点的掌握程度吧!
评论区
使用 GitHub 账号登录后即可发表评论,支持 Markdown 格式。
如果评论系统无法加载,请确保:
- 您的网络可以访问 GitHub
- giscus GitHub App 已安装到仓库
- 仓库已启用 Discussions 功能